
In this blog, I will try to explain the recommender system in python with a particular focus on the Movie recommendation system using Python programming language. This blog is the first in a series of movie recommendation systems. At the end of every blog, you will find the link to the next blog. So let’s get started!
What is a Recommender System?
Recommender systems can be understood as systems that make suggestions. We often ask our friends about their views on recently watched movies. Based on that, we decide whether to watch the movie or drop the idea altogether. Imagine if we get the opinions of the maximum number of people who have watched the movie. We also get ideas about similar movies to watch, ratings, reviews, and the film as per our taste.
Selection of Movies would become so easy; don’t you think so?
That is what Recommender systems usually do. They help us make a selection, narrow down our search, and enjoy the selected list of movies without wasting time searching for which movie to watch.
Recommender systems typically produce a list of recommendations in one of two ways – either by Collaborative or Content-based filtering.
- Collaborative filtering approaches build a model from a user’s past behavior as well as similar decisions made by other users. This model is then used to predict items for an active user.
- Content-based filtering approaches utilize a series of discrete characteristics of an item in order to recommend additional items with similar properties.
- These approaches are often combined in Hybrid Recommender Systems.

It is time to roll up your sleeves and get started with building our recommender system.
DataSet
We will work with two datasets. One is Credits, and the other is Movies The dataset is taken from Kaggle, it is called TMDB data i.e. The Movie Database. You can download the dataset from here, this is the Kaggle website.
Getting Started
Load the basic libraries, load the datasets and explore the basic details like the shape of the data, null value, and data types of each column. The two datasets are also merged on the ‘id’ column. Click on the arrows in the slideshow to move to the next code snippet.
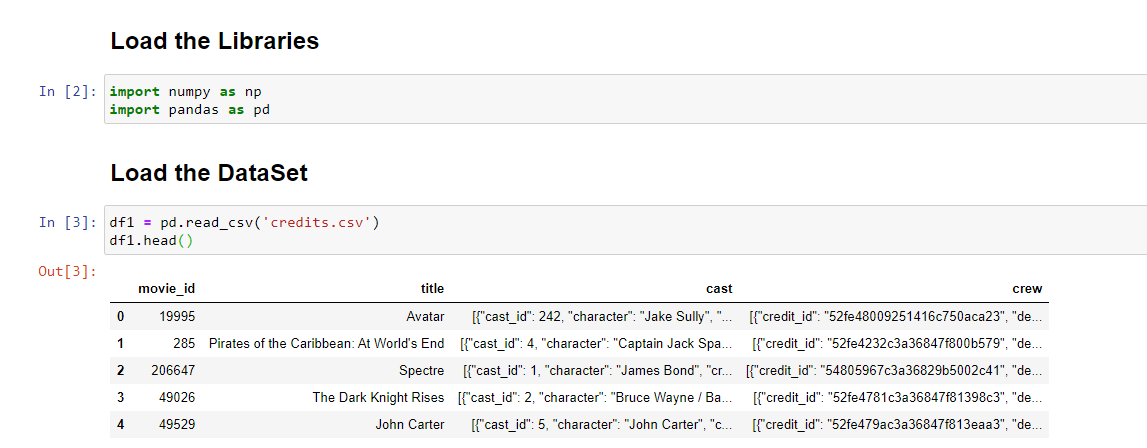



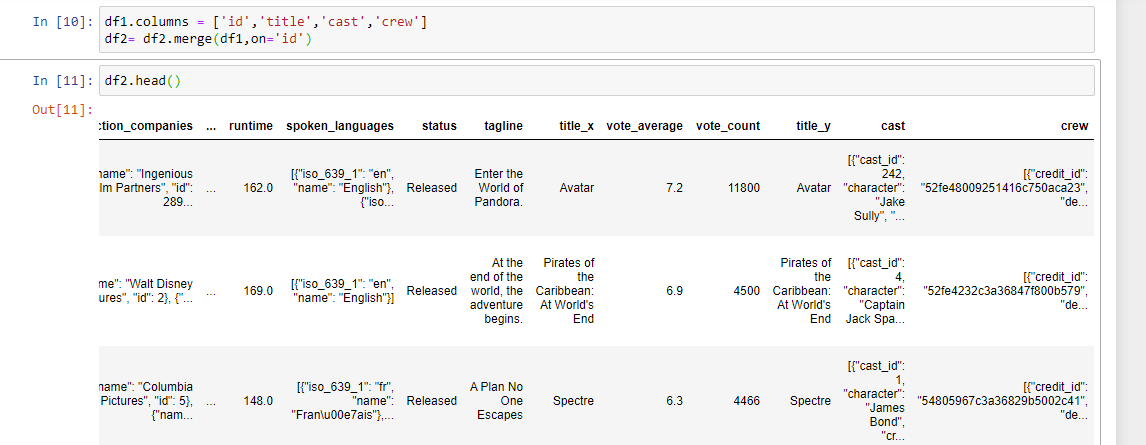

Details of the dataset
- The first credit dataset contains 4803 rows and 4 columns.
- The second movie dataset contains 4803 rows and 20 columns
- To perform the further analysis we need to merge the datasets on the ‘id’ column.
Let us dig a little deeper to make more sense.
- We need a metric for rating the movie
- We need to Calculate the score for every movie
- Sort the scores and recommend the best-rated movie to the users.
A simple way to find the score is to go with the average ratings, but using this won’t be fair enough since a movie with an 8.7 average rating and only 8 votes cannot be considered better than the movie with 7.9 as an average rating but 40 votes. So, let us use IMDB’s weighted rating (wr) which is given as:-

where,
- v is the number of votes for the movie;
- m is the minimum votes required to be listed in the chart;
- R is the average rating of the movie; and
- C is the mean vote across the whole report
We already have v(vote_count) and R (vote_average) and C can be calculated as
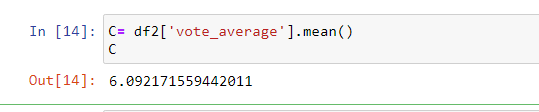
Thus, the mean rating for the listed movies is 6 on a scale of 10.
The next step is to determine an appropriate value for m, the minimum votes required to be listed in our list of good movies. We will use the 90th percentile as our cutoff. In other words, for a movie to feature in the list, it must have more votes than at least 90% of the movies on the list.
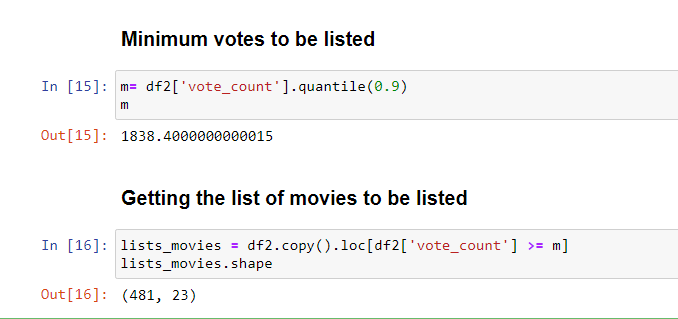
There are 481 movies that qualify to be on this list. Let us calculate our metric for each qualified movie. To do this, we will define a function, weighted_rating(), and define a new feature score, of which we’ll calculate the value by applying this function to our DataFrame of qualified movies:
Then we will sort the Data Frame based on the score feature and output the title, vote count, vote average, and weighted rating or score of the top 10 movies.


Thus, we get the list of top 10 movies as per their score, title, and average score.
We have made our first very basic recommender system. Under the Trending Now tab of these systems, we find movies that are very popular and they can just be obtained by sorting the dataset by the popularity column, or budget column.

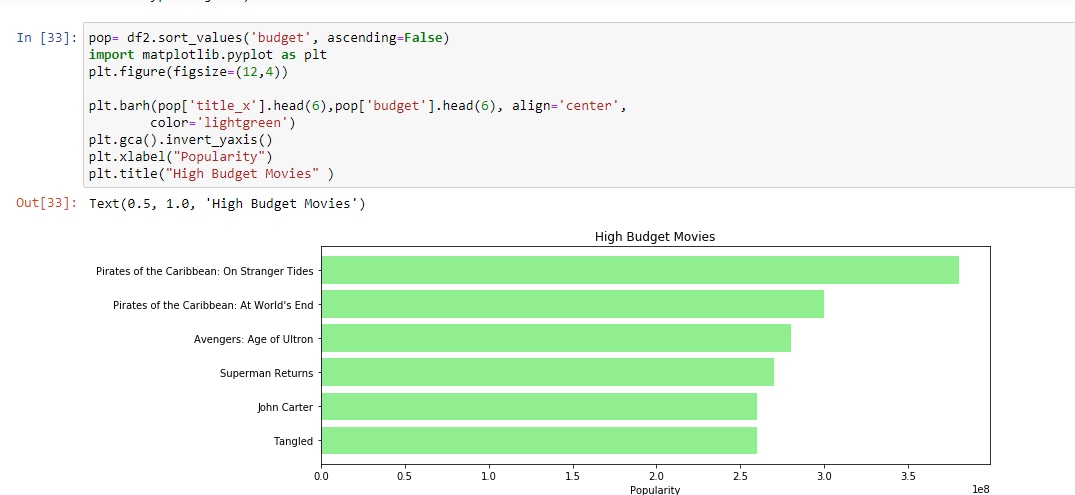
Watch out for the complete process of building Movie recommendations in python.
What’s Next
The basic recommender system provides the same content to all users. It is not user-specific, not will give filtered movies based upon the user’s taste and preference. Thus we need a more refined system called Content-Based Filtering.
Leave your comments in case of any doubt.
Follow the next blog for the Content-Based Filtering Recommendation System


Pingback: Content-Based Recommender System Python – Machine Learning
Pingback: Content Based Recommender System – Machine Learning
Having read this I believed it was really enlightening. I appreciate you spending some time and energy to put this information together. I once again find myself personally spending a significant amount of time both reading and commenting. But so what, it was still worthwhile!
Thank you so much for the feedback and your valuable time. It is really appreciated:)