
Before we start with building a content-based recommendation system, it is advisable to go through the previous blog to get a clear picture of what exactly we will be doing here!
We have already built a basic recommendation system in the earlier blog. For your reference, click here to get access to the previous blog, this is the first in the series of blogs Movie recommendation system python. Once you are done with the basic understanding, it will become easier to learn further concepts.
First, let us understand the need for content-based filtering.
Need for Content-Based Filtering
The suggestions and the recommendations made by the recommender engine help to narrow down the search as per our own preferences.
- The need for content-based filtering arises as we become more selective with our choices and preferences.
- When we do not wish to waste time searching for similar content.
- When we have a smart way to deal with the issue.
- We can rely on the suggestions
What are Content-Based Recommender Systems
They make recommendations based on the descriptive attributes of items. To simply put it:
Content = Description.
In content-based methods, the ratings and buying behavior of users are combined with the content information available in the items. E.g. Jane likes Terminator movies; based on the similar genre keywords other science fiction movies, such as Alien and Predator will be recommended.
What becomes the training data?
- The item descriptions, which are labeled with ratings, are used as training data. To create a user-specific classification or regression modeling problem.
- The class (or dependent) variable corresponds to the specified ratings or buying behavior.
- These training documents are used to create a classification or regression model, which is specific to the user
- This user-specific model is used to predict whether the corresponding individual will like an item for which her rating or buying behavior is unknown
Advantages and Disadvantages of Content-Based Recommender System
Advantages :
- In making recommendations for new items, when sufficient rating data are not available for that item.
- Even if there is no history of ratings for a particular item; still recommendations can be made.
Disadvantages :
- It becomes very specific to the user’s needs. The community view is ignored here. They are not effective in making recommendations to the new user.
- It is usually important to have a large number of ratings available for the target user in order to make robust predictions without overfitting.
Content-Based Filtering
Content-based filtering is built using a content-based recommender system.
Let us now compute pairwise similarity scores for all movies based on their plot descriptions and recommend movies based on that similarity score. The plot description is given in the overview feature of our dataset.
Word to Vector Conversion is needed for the column overview.
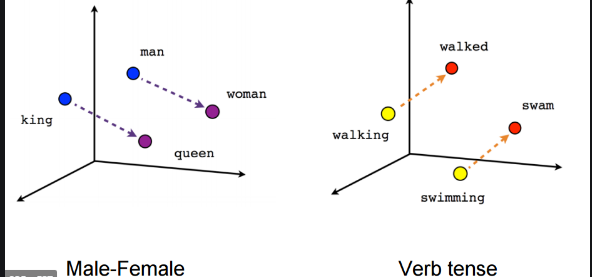
A vector is an object that has both a magnitude and a direction. Giving each word a direction and magnitude provides a way to visualize the text in space and draw meaningful insights from the data plotted.
We will Compute Term Frequency-Inverse Document Frequency (TF-IDF) vectors for each overview. The tf–idf weight is a weight often used in information retrieval and text mining. This weight is a statistical measure used to evaluate how important a word is to a document in a collection or corpus.
TF: The number of times a word appears in a document, divided by the total number of words in that document; Term Frequency, which measures how frequently a term occurs in a document.
TF(t) = (Number of times term t appears in a document) / (Total number of terms in the document).
The second term is the Inverse Document Frequency (IDF), computed as the logarithm of the number of the documents in the corpus divided by the number of documents where the specific term appears.
IDF measures how important a term is.
While computing TF, all terms are considered equally important. Few terms like: and, the, is, of, that; might appear many times but are of little significance. Hence, we need to weigh down the frequent terms while scaling up the rare ones, by computing the following:
IDF(t) = log_e(Total number of documents / Number of documents with term t in it).
Applying TF-IDF in our example; we obtain a matrix, where each column represents a word in the overview vocabulary (all the words that appear in at least one document) and each row represents a movie, as before. This is done to reduce the importance of words that occur frequently in plot overviews and therefore, their significance in computing the final similarity score.
Click on the white arrows to see the code snippets.



We have 20,978 different words used to describe the 4803 movies in our dataset.
Similarity Score
With the matrix obtained, we can now compute a similarity score. There are several ways for this; such as the Euclidean, the Pearson, and the cosine similarity score. It is often a good idea to experiment with different metrics.
We will use the cosine similarity to calculate a numeric quantity that denotes the similarity between two movies. We use the cosine similarity score since it is independent of magnitude and is relatively easy and fast to calculate. Mathematically, it is defined as follows:

Since we have used the TF-IDF vectorizer, calculating the dot product will directly give us the cosine similarity score. Therefore, we will use sklearn linear_kernel() instead of cosine_similarities() since it is faster.
We are going to define a function that takes in a movie title as an input and outputs a list of the 10 most similar movies. Firstly, for this, we need a reverse mapping of movie titles and DataFrame indices. i.e., we need a mechanism to identify the index of a movie in our metadata DataFrame, given its title.

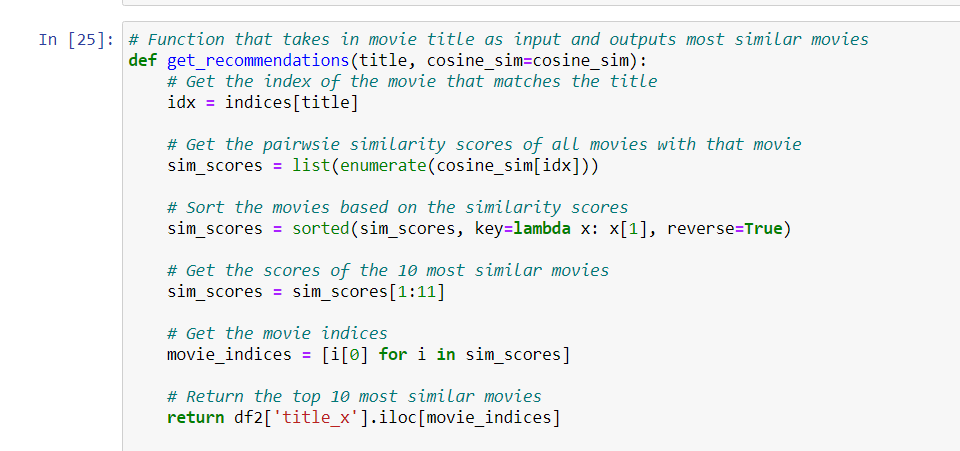
lamda signifies an anonymous function. In this case, this function takes the single argument x and returns x[1] (i.e.the item at index 1 in x).
We can now define our recommendation function. These are the following steps we’ll follow:-
- Get the index of the movie given its title.
- Get the list of cosine similarity scores for that particular movie with all movies. Convert it into a list of tuples where the first element is its position and the second is the similarity score.
- Sort the aforementioned list of tuples based on the similarity scores; that is, the second element.
- Get the top 10 elements of this list. Ignore the first element as it refers to self (the movie most similar to a particular movie is the movie itself).
- Return the titles corresponding to the indices of the top elements.


Hence, we are done with our recommender system based on plot description or based on the overview of the movie. But still, further improvements can be made by making Recommendations based on cast, crew, and genre.
For the next part visit the other blog where we build a final content-based recommendation system.
Watch out for the complete process of building Movie recommendations in python here, a video tutorial.
Sources:
- http://www.tfidf.com/
- https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system
- https://en.wikipedia.org/wiki/Cosine_similarity


Pingback: Movie Recommendation System Using Python – Machine Learning
Pingback: Content Based Recommender System – Machine Learning
I wish to show my appreciation for your kind-heartedness supporting folks who actually need help on this particular concern. Your very own commitment to getting the message around became unbelievably powerful and have continuously enabled professionals like me to realize their targets. The useful help and advice entails this much a person like me and a whole lot more to my fellow workers. Many thanks; from each one of us.
What抯 Happening i am new to this, I stumbled upon this I have found It positively helpful and it has aided me out loads. I hope to contribute & help other users like its aided me. Great job.
I delight in, result in I discovered just what I was taking a look for. You have ended my four day lengthy hunt! God Bless you man. Have a nice day. Bye
There are some interesting points in time on this article however I don抰 know if I see all of them center to heart. There may be some validity but I will take maintain opinion until I look into it further. Good article , thanks and we would like more! Added to FeedBurner as nicely
Hey! I could have sworn I’ve been to this blog before but after reading through some of the post I realized it’s new to me. Nonetheless, I’m definitely delighted I found it and I’ll be bookmarking and checking back often!