
It is now time to build a content-based recommendation system!
In case you landed on this blog, it is advisable to refer to the previous related blogs. This blog is the third part of the series of recommender systems. In case, you missed out on the other two parts, I am providing the links. I will be working with the same TMDB dataset
Part 1: Basic Movie Recommender System
Part 2: Content-Based Movie Recommendation System Part 1
Movie Recommender System Based on Credits, Genres, and Keywords
Let me give you a quick recap of the data, for more ease. I am working with two CSV files named movies and credits. The dataset is taken from Kaggle, it is called TMDB data i.e. The Movie Database. You can download the dataset from Kaggle.
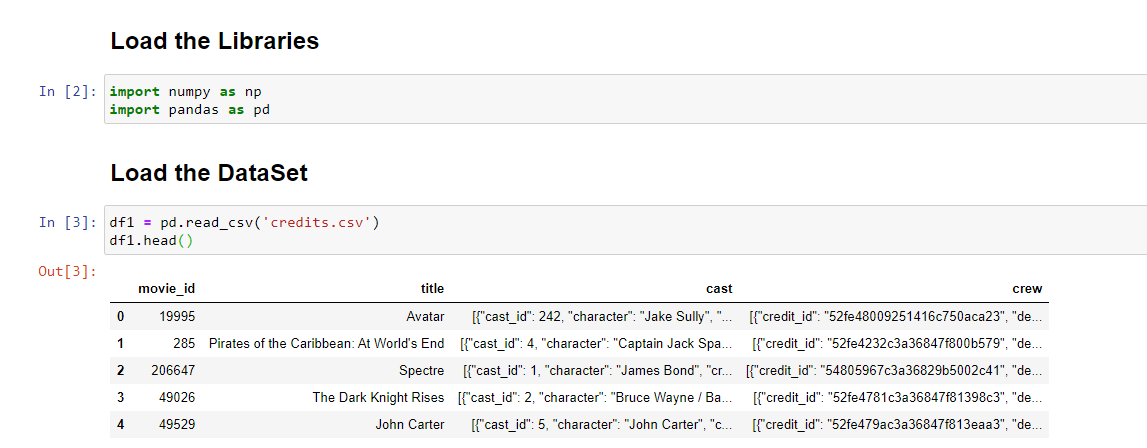



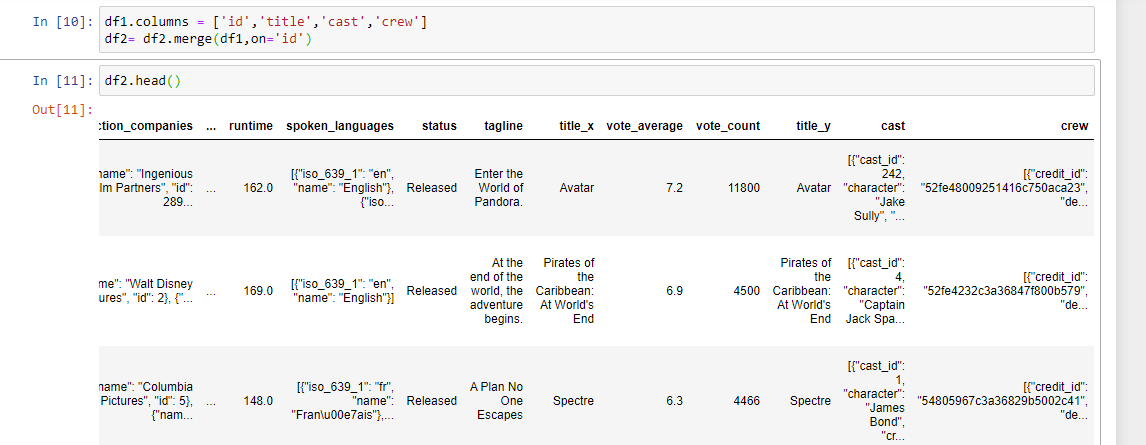
After merging the two data frames, we obtain a new data frame. We will work on this merged data frame for building a content-based recommendation system. The shape of the data frame is (4803, 24) after merging.
Now the real part begins!! We will build a more advanced recommender system in this blog, and see how we can use other features to make our recommender system more robust. We are going to build a recommender based on the following metadata: the 3 top actors, the director, related genres, and the movie plot keywords.
From the cast, crew, and keywords features, we need to extract the three most important actors, the director, and the keywords associated with that movie. Currently, our data is present in the form of “stringified” lists, we need to convert it into a safe and usable format.

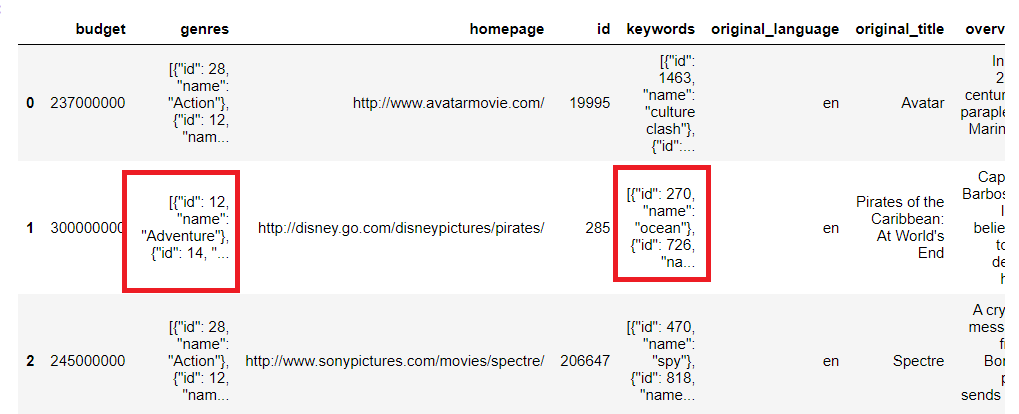
What exactly is happening here, let us try to understand: Compare the two images below and notice the red highlights. The stringified list is made clean, it is now free from” “, :, { } and other formats. These formats make it difficult to parse the rows leading to many errors.

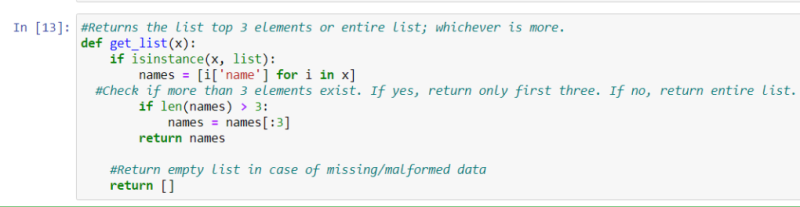
Extract Information
In order to extract information from the features, we will define functions. From the crew feature which includes: directors, editor, screenplay, casting, etc. We are using Director here. Then, we go on to get the list. As the crew column has multiple values, we give a condition to make things simple.

Now, let us extract the top 3 elements of the list, from the cast, keywords, and genres columns. For better understanding, I would suggest watching the YouTube Video, provided at the end of the blog.

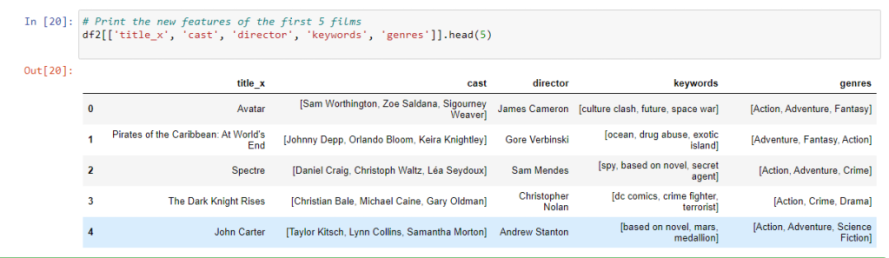
Cleaning the Data
The next step would be to convert the names and keyword instances into lowercase and strip all the spaces between them. This is done so that our vectorizer doesn’t count the Johnny of “Johnny Depp” and “Johnny Galecki” as the same.

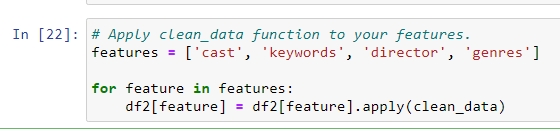
Creating Metadata
We are now in a position to create our “metadata soup”, which is a string that contains all the metadata that we want to feed to our vectorizer (namely cast, director, genres, and keywords).

The next steps are the same as what we did in the second part of the movie recommender system. Refer here.
The only difference is that we will use CountVectorizer() instead of TF-IDF. This is because we do not want to down-weight the presence of an actor/director if he or she has acted or directed in relatively more movies. It doesn’t make much intuitive sense.
Difference Between TFID and CountVectorizer
TfidfVectorizer and CountVectorizer both are methods for converting text data into vectors as models can process only numerical data.
In CountVectorizer we only count the number of times a word appears in the document which results in bias in favor of the most frequent words. this ends up in ignoring rare words which could have helped us in processing our data more efficiently. To overcome this, we use TfidfVectorizer.
In TfidfVectorizer we consider the overall document weightage of a word. It helps us in dealing with the most frequent words. Using it we can penalize them. TfidfVectorizer weights the word counts by a measure of how often they appear in the documents.
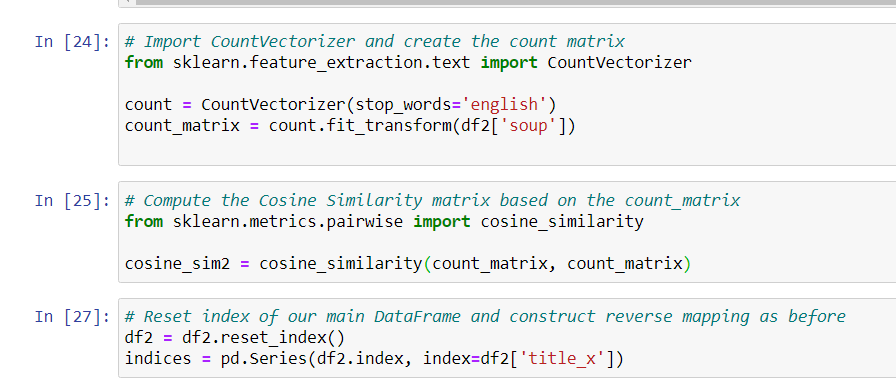
Making Recommendations
We can now reuse our get_recommendations() function by passing in the new cosine_sim2 matrix as your second argument.


Thus, our content-based recommender system is able to capture more information, as we have provided it with more metadata. We can use other features like production company if you want movies from the same production house ( like Walt Disney Pictures, or Warner Bros) based on the production_companies feature.
Finally, we have built our recommender system. Keep experimenting with other features to understand the data well.

