Decision Trees in Machine Learning are one of the supervised machine learning algorithms used for both classification and regression tasks. Decision Trees are also non-parametric, which means it does not make assumptions, unlike Naive Bayes. When we have an algorithm that does not make predictions we can obtain good prediction results too as bias is reduced.
The objective of Decision Trees
The goal of the decision tree algorithm is to create a model that predicts the value of a target variable by learning simple decision rules that are learned from the data features or columns.
The decision rules are generally in form of if-then-else statements. The deeper the tree, the more complex the rules and fitter the model.
Decision trees are a graphical representation of all the possible solutions to a decision. These decisions are based on some conditions and can be easily explained.
A decision tree is a tree-like graph with nodes representing the place where we pick an attribute and ask a question; edges represent the answers to the question, and the leaves represent the actual output or class label. They are used in non-linear decision-making with a simple linear decision surface.

Example Decision Tree Algorithm
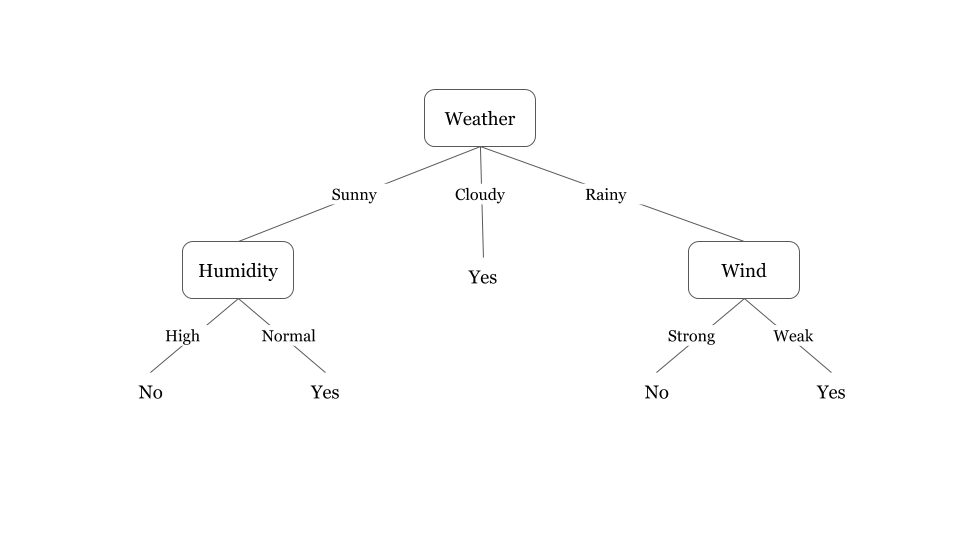
An example can help to better understand how a decision tree works. Based on the weather condition one can decide whether to play outside or not.
Advantages of Decision Trees
- Most accurate learning algorithms
- Runs efficiently on large databases
- Simple to understand, interpret, and visualize.
- Decision trees implicitly perform variable screening or feature selection.
- Can handle both numerical and categorical data. Can also handle multi-output problems.
- Decision trees require relatively little effort from users for data preparation.
- Nonlinear relationships between parameters do not affect tree performance
- Methods for balancing error in unbalanced data sets
Disadvantages of Decision Trees
- Decision-tree learners can create over-complex trees that do not generalize the data well. This is called overfitting.
- Decision trees can be unstable because small variations in the data might result in a completely different tree being generated. This is called variance, which needs to be lowered by methods like bagging and boosting.
- Greedy algorithms cannot guarantee to return of the globally optimal decision tree. This can be mitigated by training multiple trees, where the features and samples are randomly sampled with replacement.
- Decision tree learners create biased trees if some classes dominate. It is therefore recommended to balance the data set prior to fitting with the decision tree.
Concluding Thoughts
Decision trees are good to go Machine Learning Algorithm, can be used in most Machine Learning tasks. An improvement over the Decision Tree is Random Forest. Random Forest overcomes a few disadvantages of the Decision tree.
An advancement over Decision Trees is Random Forest, read more about Random Forest Algorithm.

